The Excel pricing workflow—replaced, not patched.
Every GovCon firm that prices seriously has a pricing model. The model is usually good. The workflow around it is where the time goes—and where the errors come in.
Here is what the pricing workflow looks like today. Someone saves a copy of the master Excel file for this bid. They manually add the positions specific to this RFP. They manually enter the vehicle rates and LCATs from a separate source. They enter the indirect rates from wherever the current version lives. The model produces numbers. Finding the formula that drives a specific output means pressing F2 on cells until you locate it. When assumptions change, the version you edited and the version someone else edited need to be reconciled. Version control is whoever saved last.
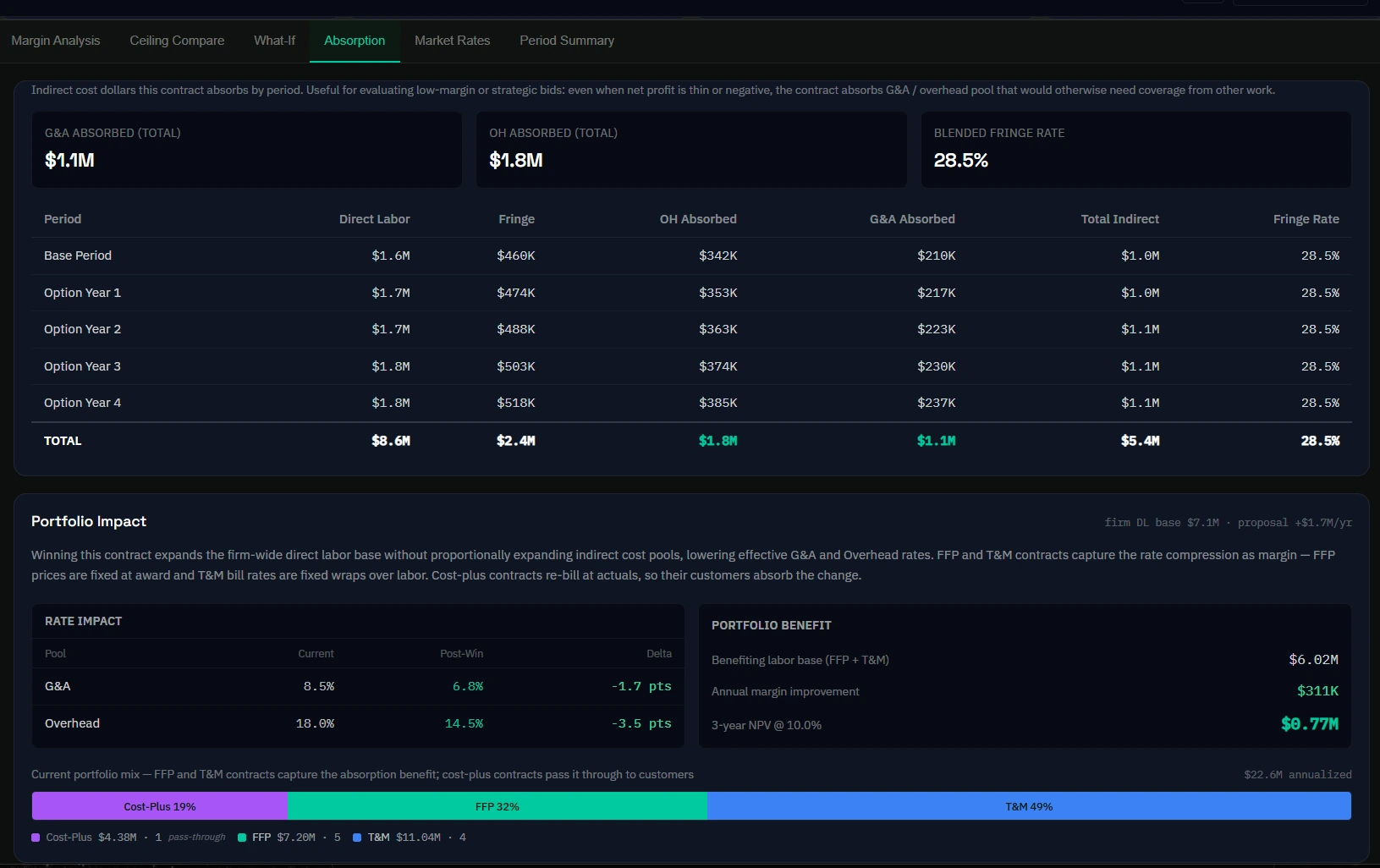
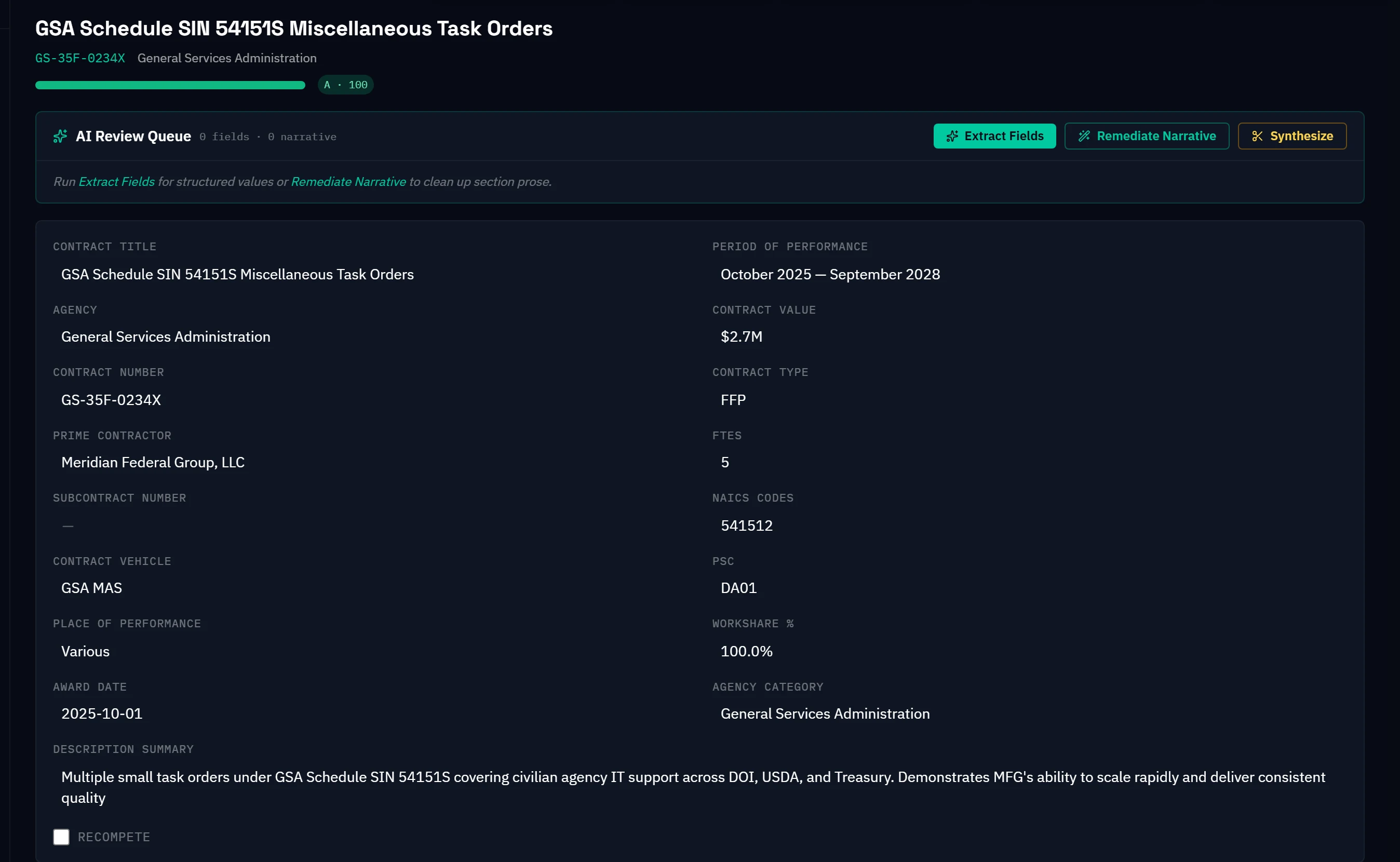
Arcvue replaces that workflow—not the quality of the underlying model, but all of the overhead surrounding it. Vehicle rates and GSA schedule LCATs are pre-loaded and maintained in the platform. Indirect rates pull nightly from your actual ERP cost pools—no manual entry, no question of which version is current. Assumptions are versioned automatically. The audit trail is built in—every derivation is transparent in the interface, not traced by pressing F2. When submission comes, the pricing audit walks through compliance checks and produces a formal attestation with digital signoff.
Contract vehicle libraries carry your ceiling rates for GSA MAS, OASIS+, and other vehicles. Each position maps to the correct Labor Category Alignment Tool entry so LCAT matching reflects how GSA actually classifies the work—not just job title similarity. Ceiling rate headroom is visible at the position level so you know exactly how much room you have before you hit the GSA cap.
Market intelligence from GSA CALC+ shows where your rates sit relative to competitors billing the same labor categories on similar contracts. This is a validation layer against the pricing you've already built from your cost structure—not a substitute for it. You price from cost. You validate against market.
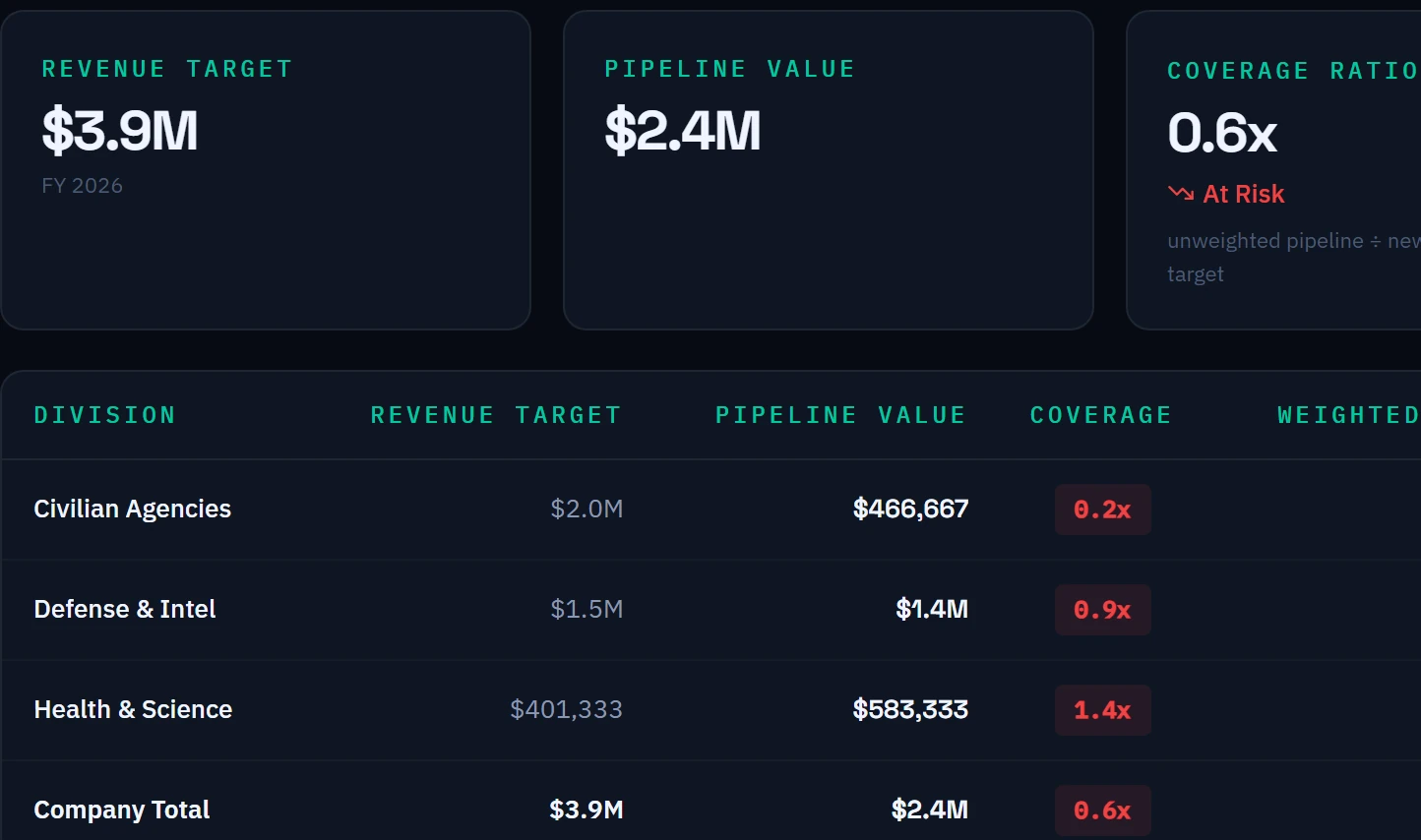
Incumbent rates are pulled directly from USAspending.gov contract obligation data. Look up any predecessor contract by PIID or recipient name, compare incumbent rates against your proposed rates position by position, and see exactly where you stand before you submit. On a recompete, this is the most important data point in the proposal.
Before submission, the pricing audit walks through a structured compliance review—contract-type-specific questions, a system comparison that flags discrepancies between your stated assumptions and what the numbers show, and a formal attestation with digital signoff for submission-grade proposals. Not a compliance stamp. A governance process that makes sure pricing and leadership are aligned on what's being submitted and why.
- Live indirect rates in every proposal—updated nightly from your actual ERP, never a static annual model
- GSA contract vehicle libraries with ceiling rates and LCAT matching by Labor Category Alignment Tool entry
- Ceiling rate headroom visible at the position level—know your GSA cap exposure before you submit
- GSA CALC+ market intelligence—see where your rates sit relative to competitors billing similar labor categories
- Incumbent rates from USAspending.gov—look up any predecessor contract, compare position by position
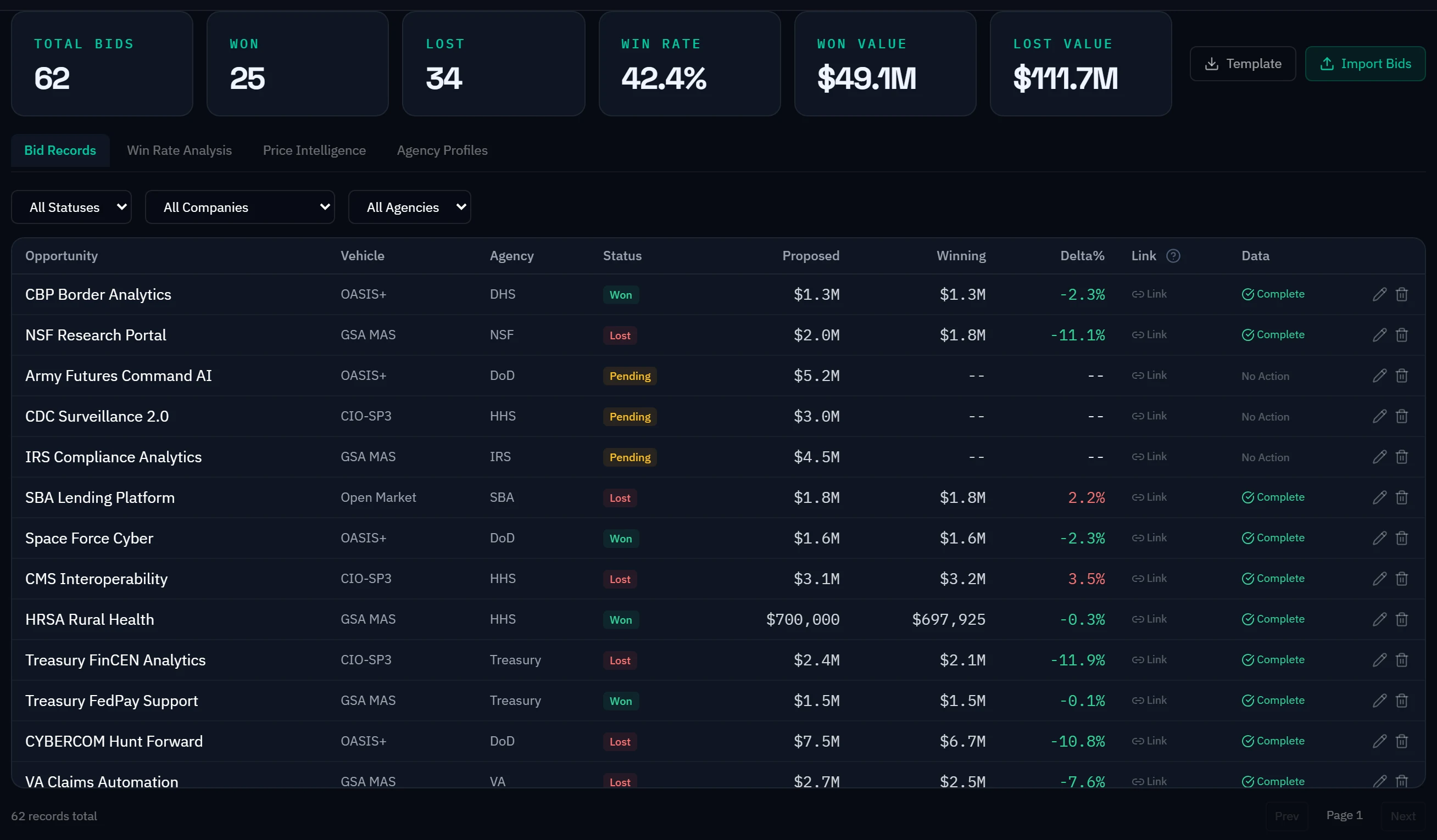
- Bid history tracking—every proposal, win/loss outcome, and competitor rate captured for institutional knowledge
- Pricing audit with formal attestation—compliance review and leadership signoff before submission
- Escalation factors, discount levels, and multiple cost pool structures supported per proposal